

El que busca tarde que temprano lo encuentra
Dicho Mexicano
Genial este es mi segundo articulo relacionado con el primer articulo del hello world. Y al parecer el programita que será la base para algo mas chido. Va progresando y si en el otro artículo hablamos de crear carpetas de una manera recursiva , Ahora sera de descargar imágenes. Y usaremos una técnica que para uno es legal y para otros no tanto. Scraping-Web. El arte de escarbar la web.
Bases
Scraping
es una técnica utilizada mediante programas de software para extraer información de sitios web. Usualmente, estos programas simulan la navegación de un humano en el WWW. Esta esta relaciona con procesos de indexado de información y transformado de la información; ideal para aquellas paginas que no poseen una API. Uno de los grandes dilemas de esta técnica es el gran debate de si es legal o ilegal en fin les dejo este articulo que nos habla un poco al respecto de este tema. Enlace
DOM
El Modelo de Objetos del Documento (DOM) es un API estandarizada por la W3C para documentos HTML y XML. Proporciona una representación estructural del documento, permitiendo la modificación de su contenido o su presentación visual. Esencialmente, comunica las páginas web con los scripts o los lenguajes de programación
RegEx
Las abreviaturas regex y regexp denotan expresiones regulares que se utilizan en la informática programación y optimización de motores de búsqueda. Las expresiones regulares se pueden utilizar para describir cadenas y números de cadenas en una forma lógica general con el fin de buscarlas, sustituirlas, manipularlas o procesarlas.
Cada uno de estos temas son muy extensos y profundizar al respecto de estos solo puede causar confusión para algo practico. Pero tener encuenta esto para escalar cualquier proyecto que se tenga de scraping.
Librerías
Como estamos en la fase de aprendizaje de python vamos a configurar nuestro entorno para darle caña a esto. Así que prepareis vuestro PIP
- Wget : https://pypi.org/project/wget/
- Requests : https://pypi.org/project/requests/
- BeautifulSoup : https://pypi.org/project/beautifulsoup4/
Existen otras librerías de scrap pero BeatifulSoup se me hizo la idónea para esto, pero echarle un ojo a scrapy y selenium
Código
Historia de usuario : Yo como analista debo entrenar una red neuronal y para eso es necesario adquirir datasets de positivos y negativos para que los algoritmos de detención funcionen correctamente.
import wget, requests
from bs4 import BeautifulSoup
class Spider:
#pagina de prueba
Page = 'https://##########/WebContent/digital_catalog_2/jsp/view_subcla###s.###?'
#Paginacion si es que la pagina lo permite si no solo agregar [none]
Pagination = 'none'
def getContentResource(self,folder,container):
_page = self.Page.strip()
if not self.Pagination == 'none' :
_params = self.Pagination.split(';')
for i in range( int(_params[0]) , int(_params[1]) ) :
page = requests.get(_page+_params[2]+str(i))
soup = BeautifulSoup(page.content, 'html.parser')
results = soup.findAll('div',{'class': container })
self._downloadImg(results,folder)
else :
page = requests.get(_page)
soup = BeautifulSoup(page.content, 'html.parser')
results = soup.findAll('div',{'class': container })
self._downloadImg(results,folder)
Para esto debemos tener conocimiento de como esta estructurado el HTML y poder acceder al DOM. Esto lo puedes hacer con la herramienta de FIREFOX de inspeccionar elementos.
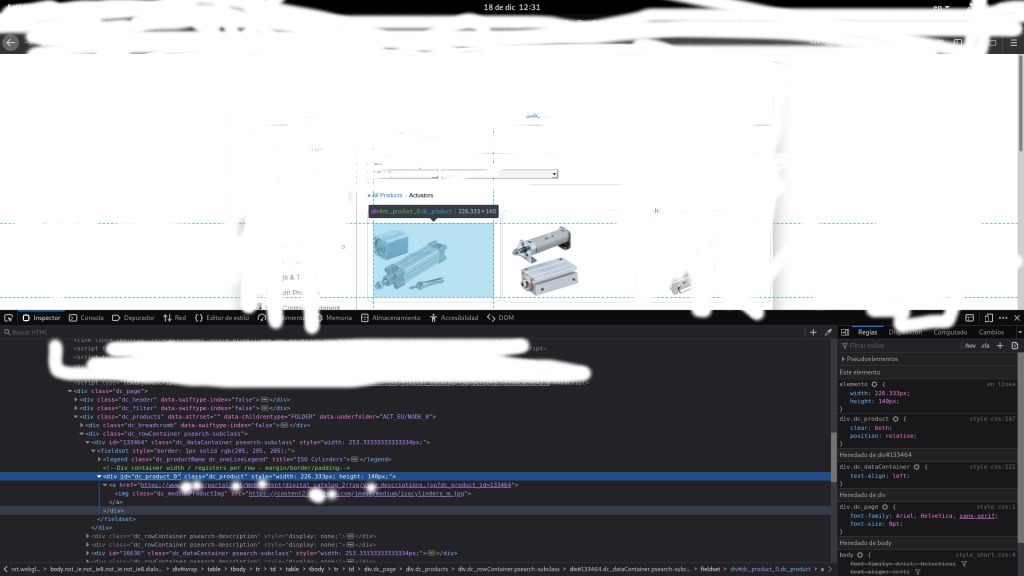
Las variables Page es la url de la pagina scrapear ejemplo Page = ‘https:www.junglacode.org’ y Pagination la cual te da la posibilidad interactuar con un catalogo que permita parámetros por GET, En caso que no con se coloque la leyenda ‘none’. En caso contrario necesitara ver cual es el request que le enviara la petición ejemplo :
www.elperro.com/productos/1
Como se podran dar cuanta ustedes podran interactuar con 1 hasta donde acabe el catalogo. En esta caso las variables quedara :
Page = ‘www.elperro.com/’ y Pagination = ‘1;11;productos/’. #Pagination esta separa por ‘;’ donde el primer carácter es numero inicial del catalogo el segundo el limite del catalogo y tercero La petición GET para acceder a cada pagina
La función getContentResource(self,folder,container) . Necesita un ruta <<folder>> en donde se va almacenar las imágenes y un contenedor<<container>>. Que no es mas que la clase de la capa que contiene la imagen en este caso como en la imagen anterior de ejemplo la capa contenedora es la dc_product
#Ejecución del script
peter = Spider()
peter.getContentResource('.','dc_product')
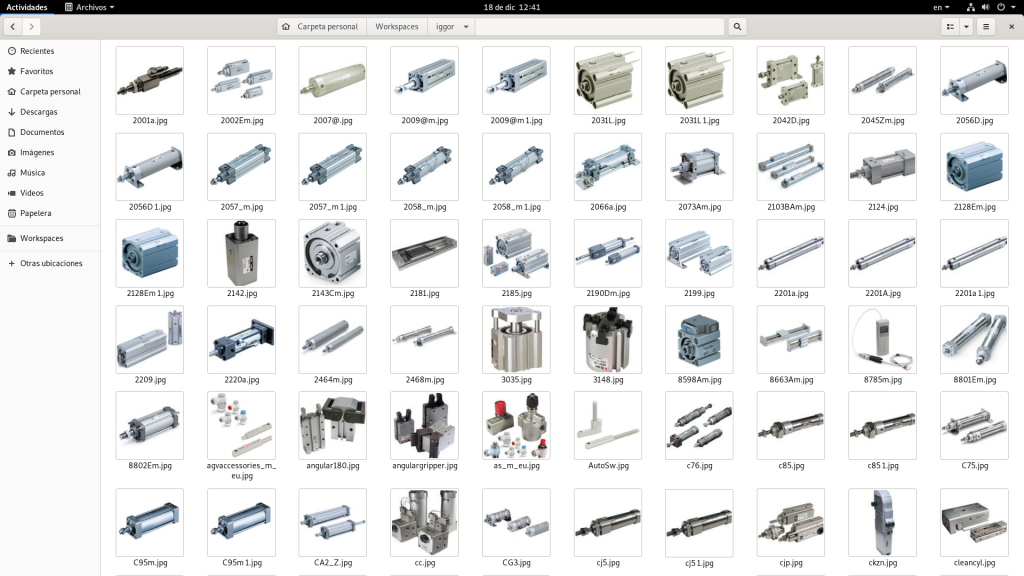
Bueno pues por lo visto el script funciona hay mejoras que se tiene que hacer como implementaciones para peticiones AJAX. Login automático , Evitar que el script sea detectado como un BOT en fin. Seguiré informando sobre este programita. Hasta la próxima queridos lectores y únicos amigos
Referencias
https://developer.mozilla.org/es/docs/DOM
https://es.ryte.com/wiki/RegEx
Soy Juan Luis García Corrales, mi nombre de guerra es monolinux. Vivo en Villagrán ,Guanajuato. Cofundador de jungla
ISC orgullosamente LINCE. Apasionado del arte , Crítico de las Películas , Musica y Libros , Escribo en tiempo libres y ♥ Regina
Mi estilo de vida es la programación así que trato de sincronizarlo con mi vida diaria, predicó la filosofía Gnu/Linux para brindar opciones menos capitalistas.
– Viviendo en la armonía del caos