
Hola amigos, como mi primer post en la trinchera me gustaria compartirles un proyecto que he realizado con la finalidad de ahorrarnos un poco de tiempo a la hora de trabajar con documentos que requieran eliminar alguna palabra o nombre dentro de este, este proyecto tiene un uso muy limitado, sin embargo conozco personas a las que espero y les ayude bastante.
La idea de este proyecto, surgió entre una platica entre su servidor y el Ing. Juan Luis, cuando después de haber hablado de los avances y metas a cumplir de un proyecto que llevamos en común, le comente lo que había estado haciendo últimamente con Python, una de estas cosas fue haber automatizado la captura y formateo de una hoja impresa de datos, a una DB utilizando el OCR de la librería Tesseract.
Fue entonces cuando el ingeniero me comento que había tenido la idea de hacer esta misma herramienta que les presento hoy utilizando Tesseract, por lo que le pedí que me dejara hacerla.
Este script actualmente cuenta con las siguientes funciones:
- Borrar múltiples palabras de un solo archivo PDF.
- Borrar múltiples palabras de varios documentos PDF dentro de una carpeta.
- Crear carpetas por cada documento con sus resultados dentro de estas.
Les dejo unas capturas de la funcionalidad general de este script:
Ingresando nombres a borrar, como tambien el path del folder.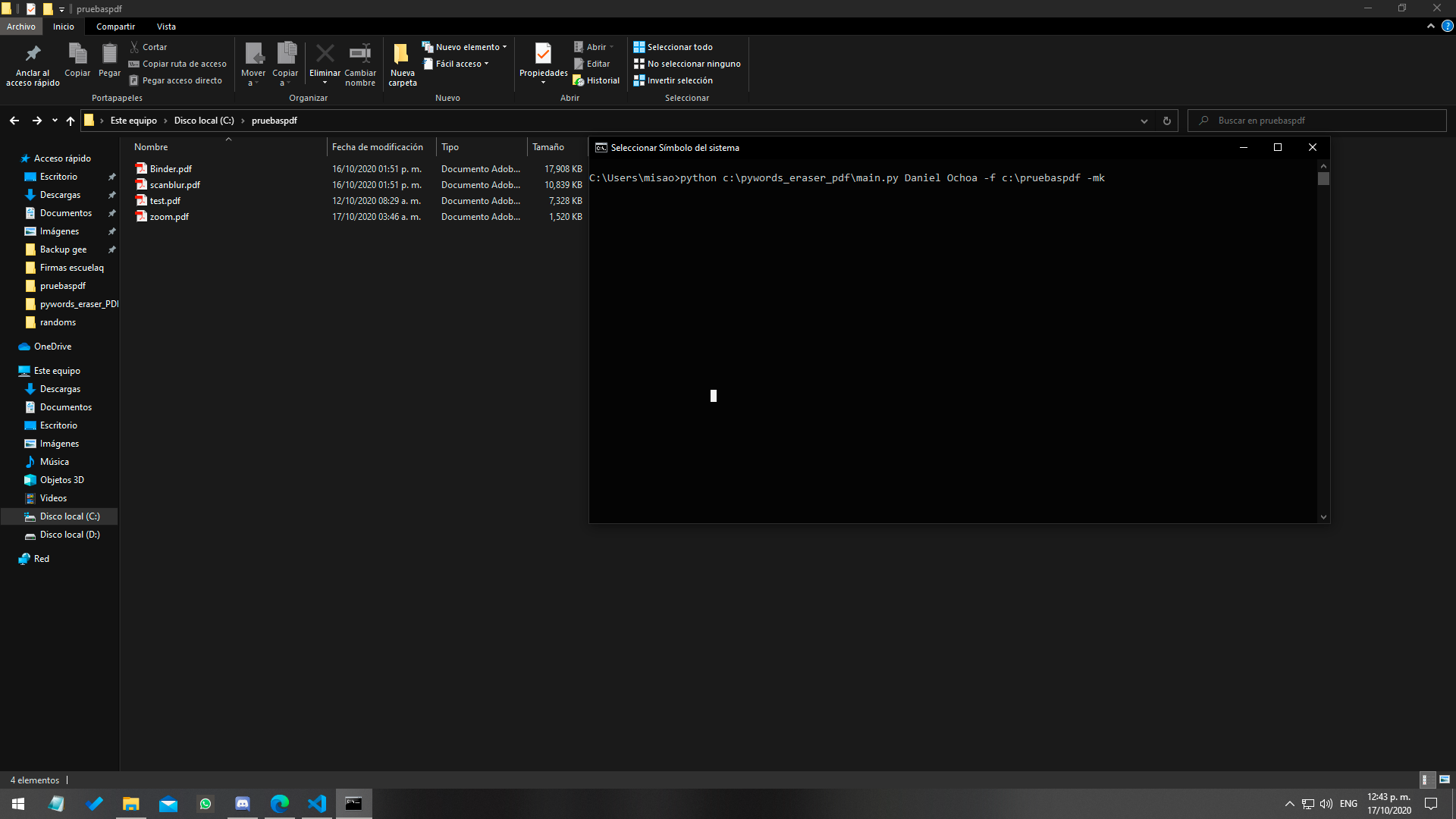
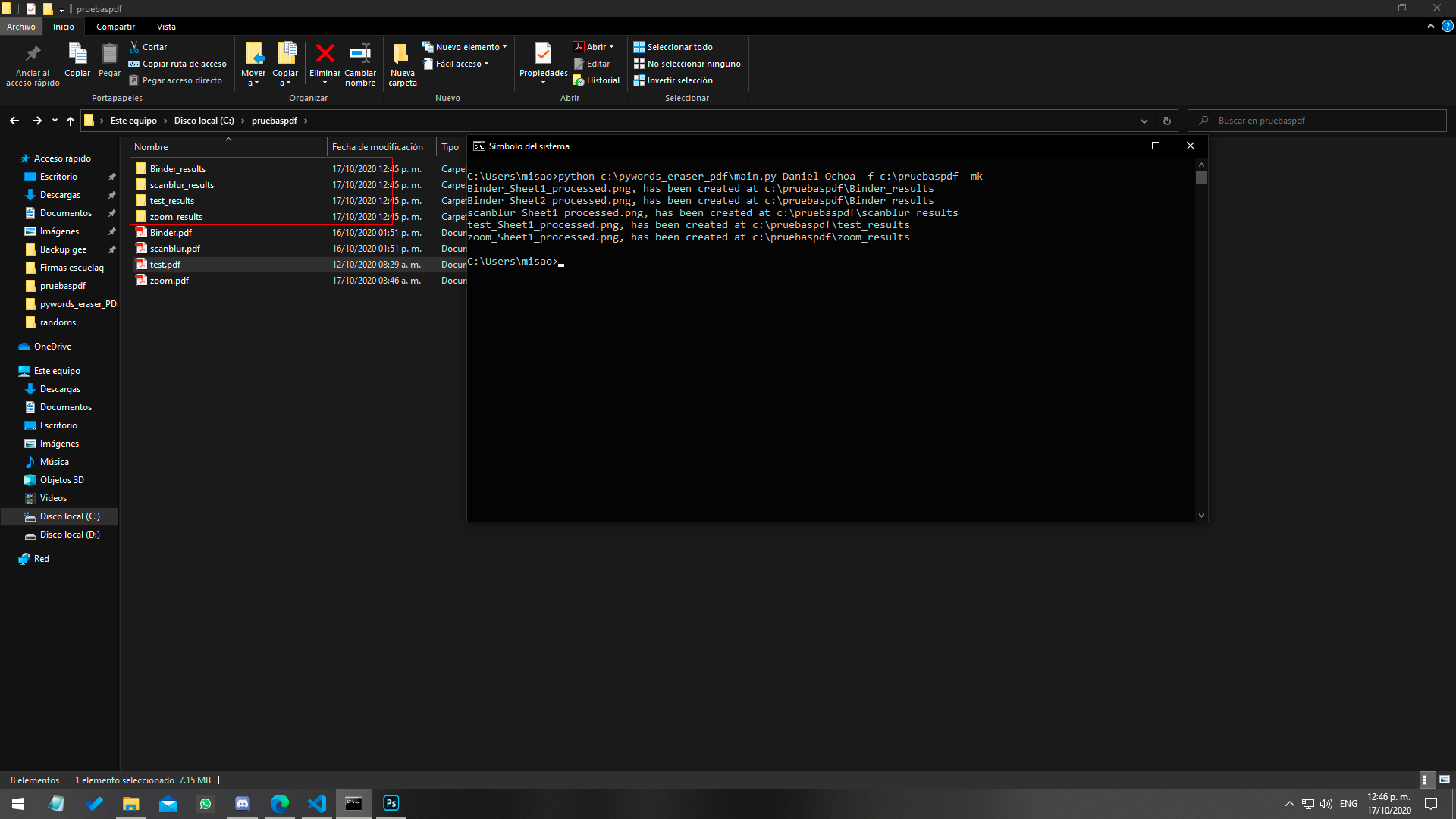
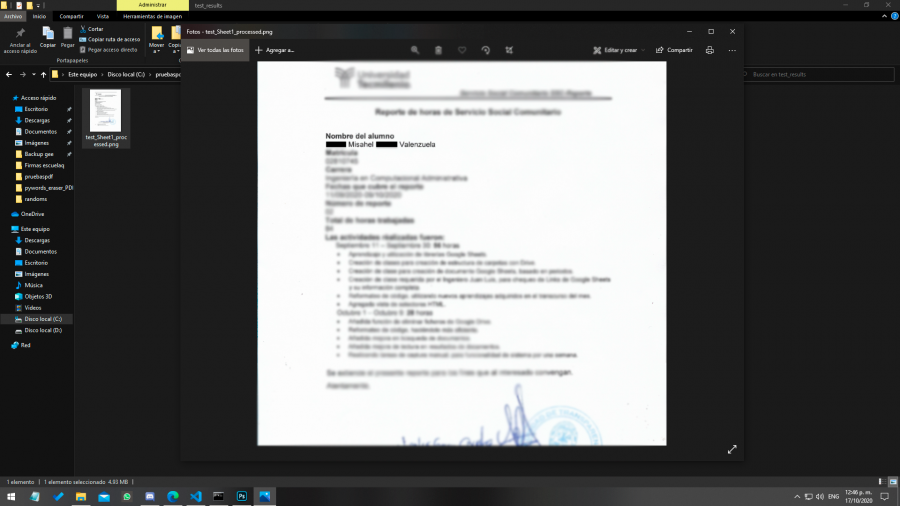
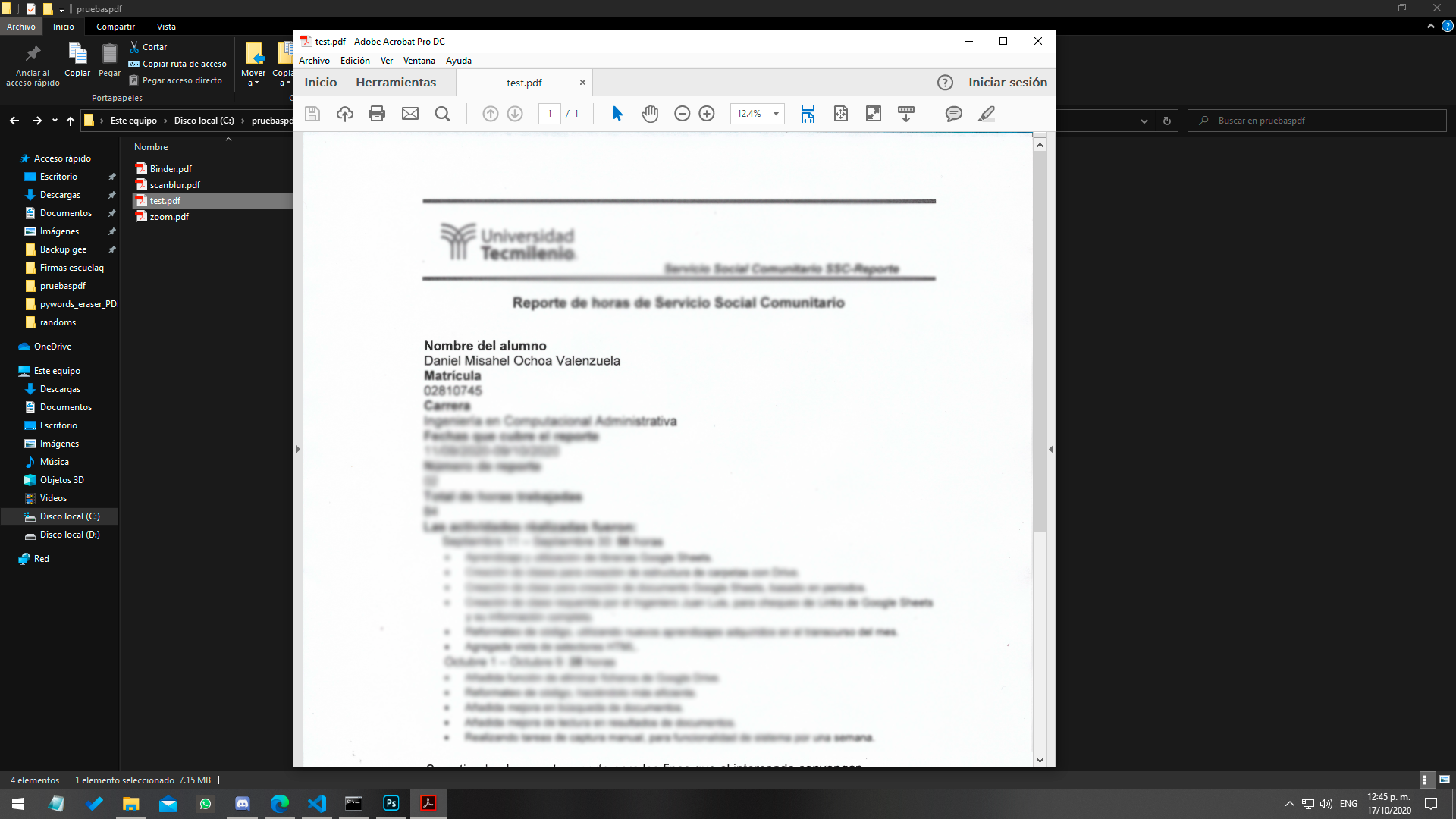
Resultado final, archivos censurados. 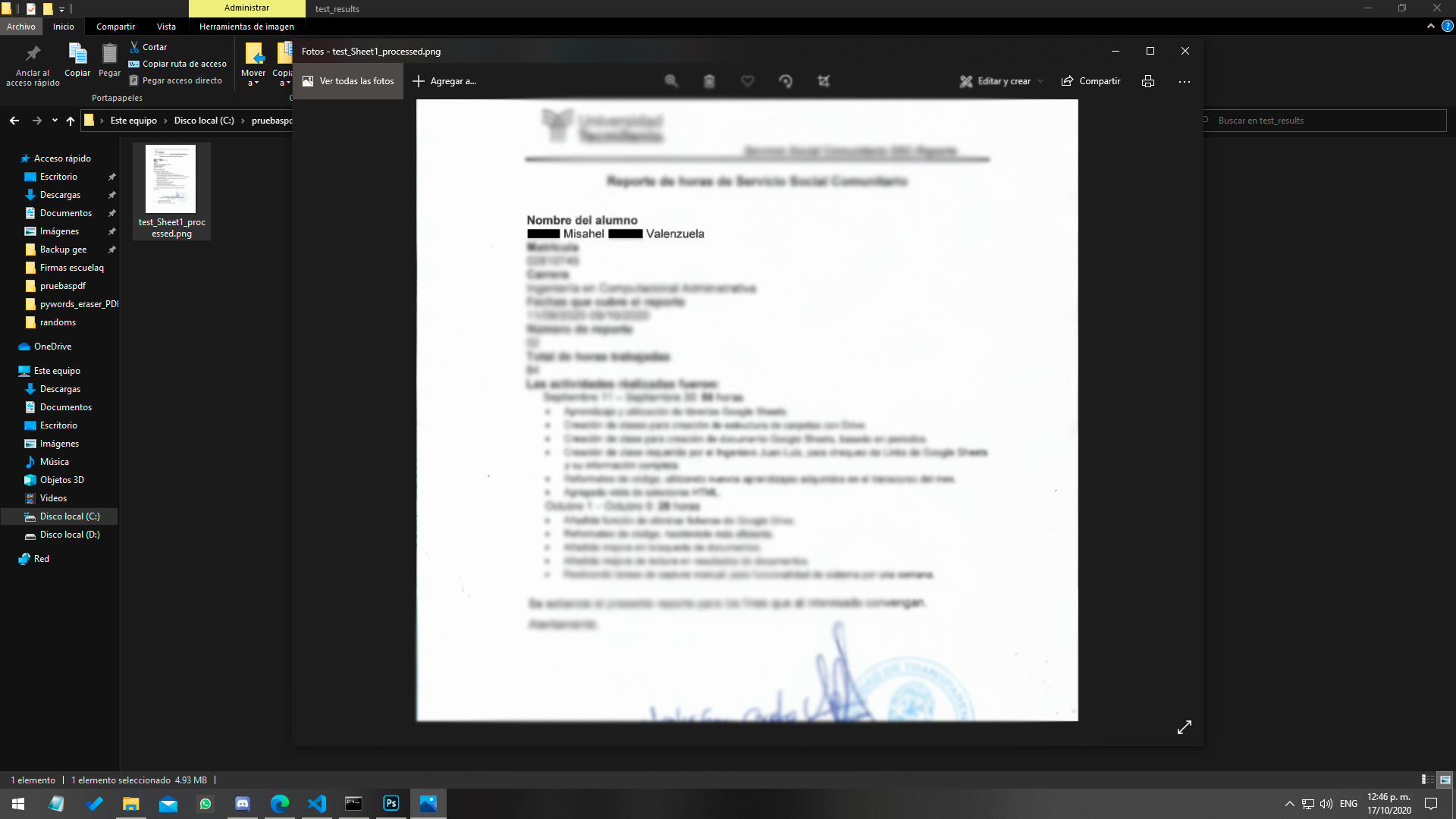
Bueno, sin mas por el momento les dejo el enlace de mi GitHub, donde se puede encontrar este pequeño script.
https://github.com/misaov/pywords_eraser_PDF
CHEERS!

Originario de la N, Sonora, tierra de las carnitas asadas.
Programador PLC Siemens, Python – Aprendiendo a programar PHP, noob en linux
excelente articulo y larga vida al software libre